
As you probably know, every version of Xojo includes an extensive list of release notes that is included in the Documentation folder as an HTML file called ReleaseNotes.htm.
To make these even easier to access, I needed a way to get these into the wiki. It would be easiest if I could just copy and paste the HTML contents onto a wiki page, but MediaWiki can’t quite process all the HTML in that file so I needed a way to clean it up a bit.
Take a look at a single line that contains a release note:
<tr class="spacer"><td class="reportid"><a href="feedback://showreport?report_id=52522">52522</a></td><td class="category">Framework » All</td><td class="desc">Added AntiAliasMode property on Graphics class. This property controls the level of interpolation/quality when drawing scaled Pictures. Valid modes are from the Graphics.AntiAliasModes enumeration: LowQuality, DefaultQuality, and HighQuality. The default is DefaultQuality.</td></tr>
This is a row in an HTML table. The problem is the <a href> part which MediaWiki does not use for displaying links. So I needed a way to clean that up. There are also some <tbody> tags that I needed to remove.
Normally I’d crack my knuckles and start on a Xojo project and use string find/replacing to massage the text. But this is messy and tedious.
So I thought, why not try Regular Expressions (RegEx)? I don’t really know much about RegEx and frankly they scare me a bit. After all, who can make heads or tails of something that looks like this:
\b(\d{1,2})([/-])(\d{1,2})\2(\d{4}|\d{2})\b
That gibberish above is called a RegEx pattern and apparently that one is for date validation.
Anyway, I figured I would give RegEx a try. My first challenge was to find a pattern that I could start with and maybe modify. Heading to the Xojo doc pages for the RegEx class, I found this pattern to remove HTML tags from text on the RegEx.Replace page’s Sample Code:
<[^<>]+>
Since I did need to remove HTML tags, I figured it was a good place to start.
To explain this pattern:
- The “<” is the starting character
- The “[” bracket starts a character class
- The “^” means not, so “^<>” means all characters except “<” and “>”
- The “]” ends the character class and the “+” means match 1 or more characters
- End with a “>” character
So that means match all the text that starts with a “<” has one or more characters after that except “<” and “>” and ends with a “>”.
FYI: For all my RegEx testing I used RegExRX — an excellent tool for dealing with RegEx written in Xojo by long-time Xojo developer Kem Tekinay.
After starting RegExRX I put the above pattern in the Search Pattern field and pasted a small snippet of the HTML into the Source Text field. I could immediately see that all the HTML tags were matched.
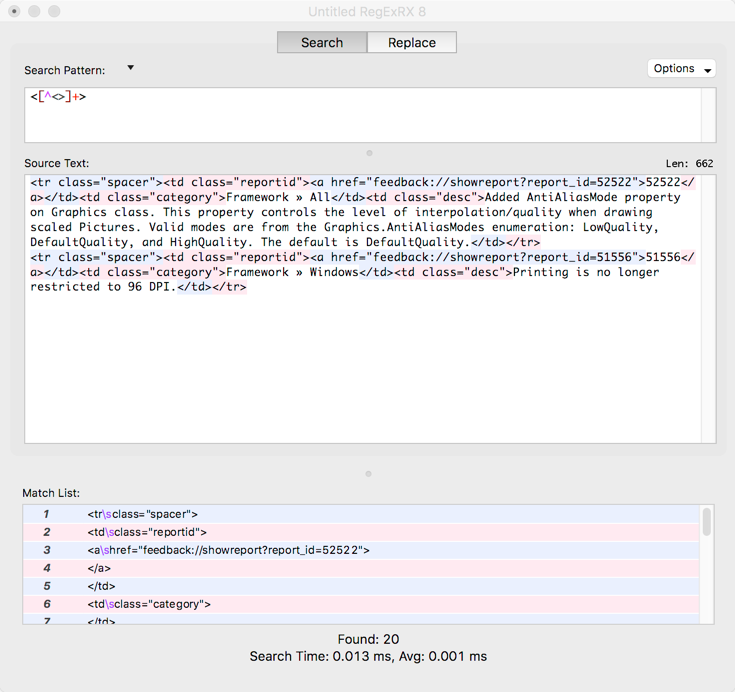
But I did not need all the HTML tags to be matched, I only needed <a> and <tbody>. A slight modification to the above pattern can tell it to only find text that starts with “<a” or “</a”. Looking at the RegEx reference on the RegEx page I saw that the “?” character means 0 or 1 matches. So I can change the pattern to this:
</?a[^<>]*>
Which means find HTML tags that start with “<a” or “</a”. With this pattern I can see that only the <a> and </a> tags are highlighted:
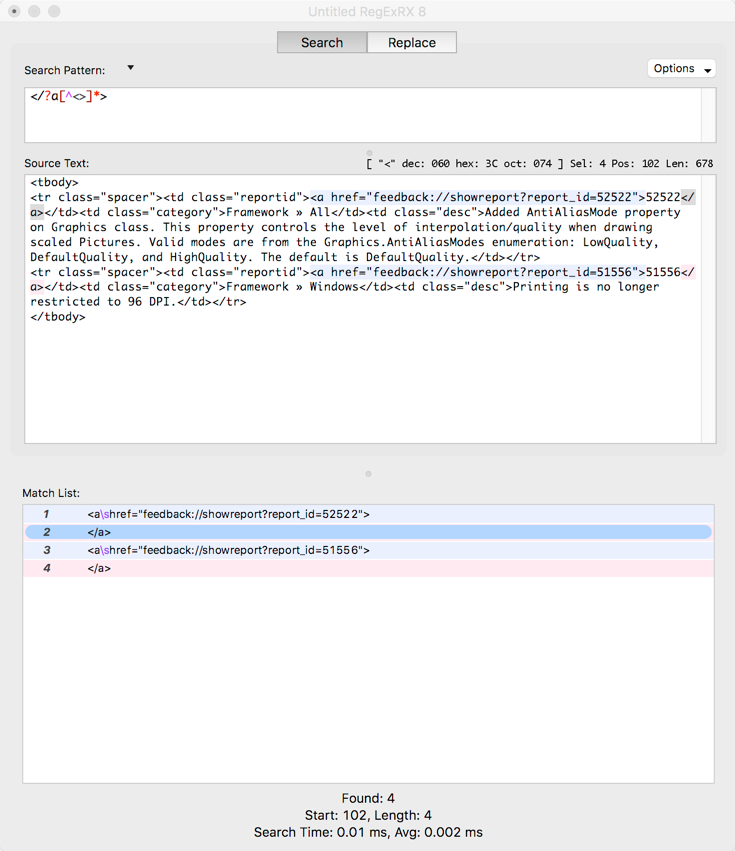
To actually remove the tags I use a Replacement and replace an empty string for the matched tag. Switching to the Replace tab in RegExRX, this is what that looks like:
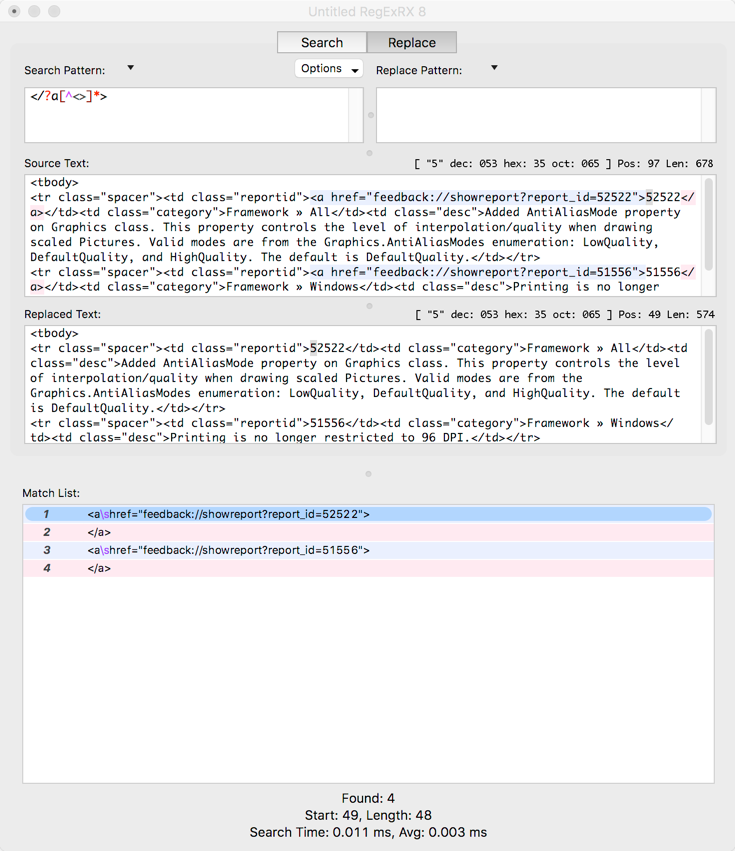
To do the same things for <tbody> I changed the pattern to this:
</?tbody[^<>]*>
Now it was time to use this in a Xojo project. You use the RegEx class to work with regular expressions. This function takes text (loaded from a release notes file) and applies the search pattern and an empty replace pattern to remove the tags and stick the result into the Clipboard so I can paste it into the wiki:
Private Function CleanHTML(html As String) as String Dim re As New RegEx re.SearchPattern = "</?a[^<>]*>" // Find <a href></a> tags for removal re.ReplacementPattern = "" re.Options.ReplaceAllMatches = True Dim plainHTML As String = re.Replace(html) // Remove any <tbody> tags as MediaWiki doesn't process them re.SearchPattern = "</?tbody[^<>]*>" re.ReplacementPattern = "" re.Options.ReplaceAllMatches = True plainHTML = re.Replace(plainHTML) Dim c As New Clipboard c.Text = plainHTML Return plainHTML End Function
This worked wonderfully, but after trying this out I decided I wanted to keep the links to the Feedback case around so that you can click on a case number to open the case in the Feedback app and read all its history. This means that instead of removing the <a> tags I needed to change them from this:
<a href="feedback://showreport?report_id=52522">52522</a>
to this:
[http://feedback.xojo.com/case/52522 52522]
To do this I now needed to use a subgroup to save the case ID so I could use it as part of the replacement string. To create subgroups you group parts of the RegEx pattern using parentheses. Essentially I wanted to have clear parts of the pattern for the <a> start tag, the value (case ID) and the </a> closing tag.
I started by simplifying the <a> tag search to this to just match the opening tag:
<a[^<>]*>
I then added a part to match the case ID which is just a series of 1 or more numbers. RegEx has a command to match only digits, which is “\d”, to which we can add the “+” to to repeat it one or more times as needed. I then wrapped that in parentheses to get a group resulting in this:
<a[^<>]*>(\d+)
Lastly I added the part to match the closing tag </a> to get the final pattern:
<a[^<>]*>(\d+)</a>
In the end you can see the <a>, </a> tags and the case ID value are all matched:
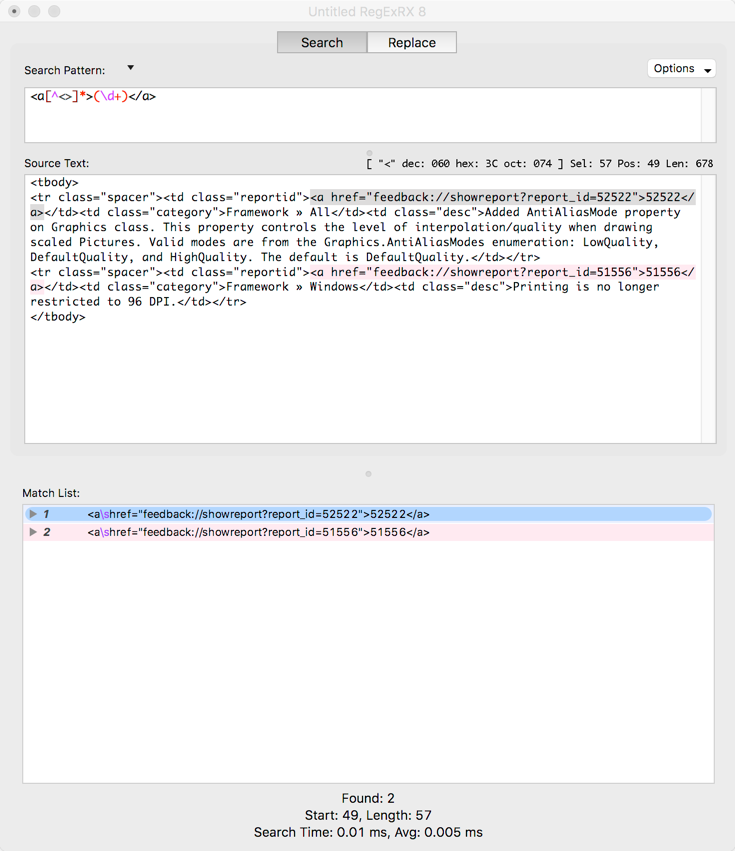
This changed pattern means I now have a group I can use for the replacement. Switching to the Replace tab in RegExRX you’ll notice that the entire matched text is removed because the Replace Pattern is blank. Typing “$1” (this contains the group with the Case ID value) in the Replace Pattern showed the Case ID in the replaced text:
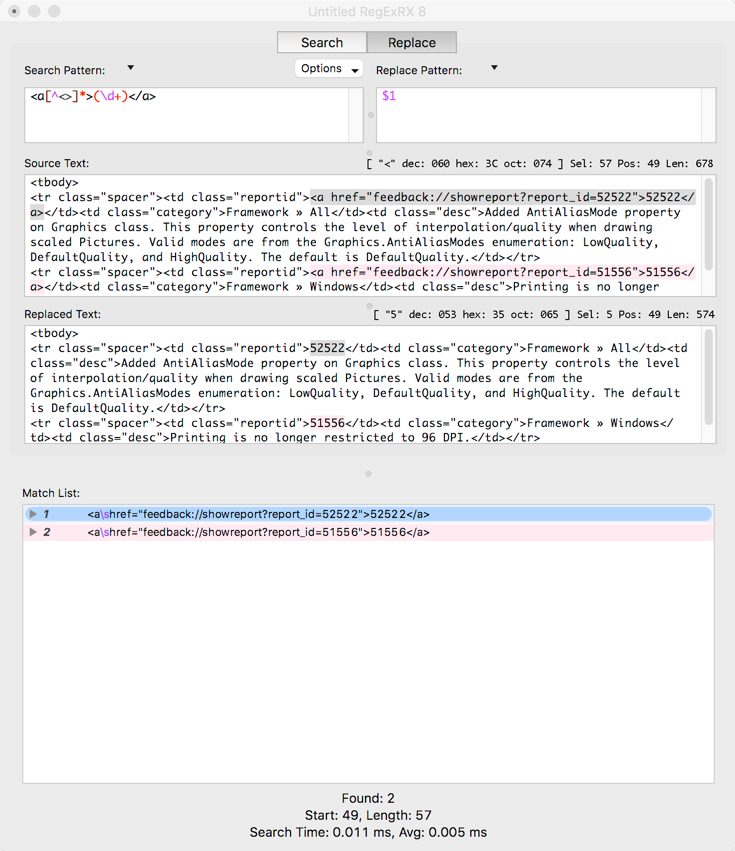
And now I put the rest of the text I wanted for the Replace Pattern:
[feedback://showreport?report_id=$1 $1]
The replaced text now looks like what I wanted:
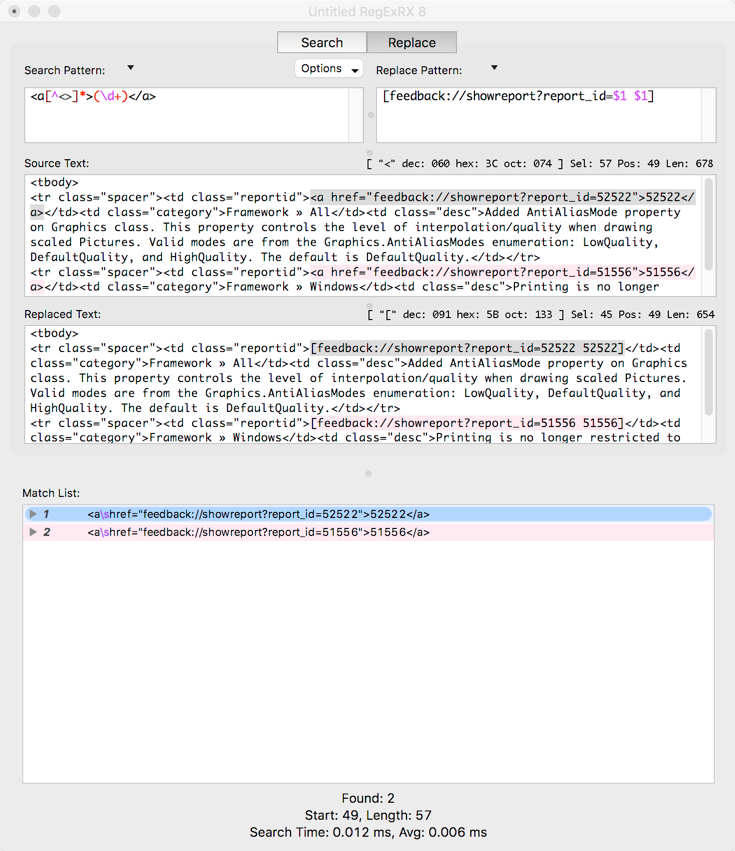
Here is the updated Xojo function:
Private Function CleanHTML(html As String) as String Dim re As New RegEx re.SearchPattern = "<a[^<>]*>(\d+)</a>" // Find <a href> tags and save case # as a group re.ReplacementPattern = "[http://feedback.xojo.com/case/$1 $1]" // Swap in wiki link format with correct URL re.Options.ReplaceAllMatches = True Dim plainHTML As String = re.Replace(html) // Remove any <tbody> tags as MediaWiki doesn't process them re.SearchPattern = "</?tbody[^<>]*>" re.ReplacementPattern = "" re.Options.ReplaceAllMatches = True plainHTML = re.Replace(plainHTML) Dim c As New Clipboard c.Text = plainHTML Return plainHTML End Function
I hope this little adventure in RegEx has helped you appreciate how wonderful they are for string searching and replacement. I’m still no expert, but I found this to be much, much better than messy string searching and parsing using InStr and friends.
To learn more about Regular Expressions, check out the RegExOne site.